




L’apprentissage automatique n’a rien d’une magie noire ni d’un gadget. C’est une mécanique de calcul, froide, patiente, qui transforme la masse brute des données en matière intelligente. Mais cette intelligence n’existe pas dans le vide : sans données à analyser, sans matière première, l’ordinateur reste muet, incapable d’apprendre. C’est là que le Big Data entre en jeu, révélant toute la puissance de l’apprentissage automatique. Ces deux mondes sont indissociables, et comprendre pourquoi, c’est percer le secret de l’intelligence artificielle moderne.
Qu’est-ce que l’apprentissage automatique ?
Malgré son nom qui a traversé les époques, l’apprentissage automatique reste parfois un terrain mal exploré dans l’esprit du grand public. S’il fallait résumer cette discipline, ce serait la capacité à détecter des motifs cachés, à anticiper des comportements à partir d’une grande quantité de données. Il est question ici de reconnaissance de formes, de prédictions. Dès les années 1950, des précurseurs comme le Perceptron ont ouvert la voie à cette transformation silencieuse.
A voir aussi : Jeux et jouets en bois : l'apprentissage par le jeu naturel

Cet apprentissage automatique fonctionne différemment des méthodes traditionnelles. Face à un océan d’informations, il avance bien plus vite et va au-delà du regard humain ou d’une analyse labourieuse. Pensez par exemple à la détection de fraude : un algorithme, en quelques millisecondes, croise quantité de paramètres (montant, lieu, historique, interactions sociales…) pour signaler une opération douteuse. Il s’agit de prouesses impossibles à réaliser, même pour les meilleurs experts armés d’outils classiques.
Lire également : Pourquoi l'enseignement primaire pose les bases de l'apprentissage
L’apprentissage automatique s’inscrit dans le grand ensemble de l’intelligence artificielle. Il s’appuie sur des algorithmes capables de construire des modèles à partir de données variées, sans se contenter d’exécuter une série de consignes préétablies. Un logiciel traditionnel applique toujours la même routine ; un système basé sur l’apprentissage automatique, lui, évolue grâce à l’expérience. Plus il accumule de données, plus il devient lucide dans ses prévisions.
Les différents types d’algorithmes d’apprentissage automatique
Derrière le terme “machine learning” se cachent plusieurs familles d’algorithmes, qui peuvent globalement être classées dans deux principaux courants : les méthodes supervisées et les non-supervisées.
Pour mieux comprendre leurs différences, voici ce qui les distingue :
- L’apprentissage supervisé s’appuie sur des données étiquetées. La machine sait où elle va : elle apprend à repérer des catégories (modèles de classification) ou à prédire une valeur numérique (algorithmes de régression).
- L’apprentissage non supervisé, lui, part de données sans indication préalable. L’algorithme enquête librement, découvre des similarités et met au jour des liens inattendus. C’est un atout en cybersécurité notamment, pour attraper des comportements étranges. Dedans, on retrouve des méthodes de clustering, d’association ou encore de réduction de dimensionnalité.
Il existe aussi une approche intermédiaire : l’apprentissage par renforcement. Ici, l’algorithme teste différentes actions pour remplir une mission, et il reçoit des encouragements ou des avertissements selon ses choix. C’est grâce à ce procédé que l’on observe des intelligences artificielles capables de maîtriser des jeux complexes ou de piloter certains robots autonomes.
À quoi sert l’apprentissage automatique ?
Utilisation et applications
L’apprentissage automatique s’est inséré partout, sans bruit, dans la vie quotidienne. Les recommandations personnalisées sur Netflix, YouTube, Amazon ou Spotify ? Ce sont des modèles qui enregistrent vos habitudes, scrutent vos préférences, puis adaptent leurs suggestions à la volée.
Derrière chaque moteur de recherche, Google, Baidu,, chaque fil d’actualité de plateforme sociale, chaque assistant vocal comme Siri ou Alexa, on retrouve ce jeu d’analyse continue des faits et gestes des utilisateurs. Chaque clic, chaque mot-clé, chaque like est une donnée qui affine en temps réel la pertinence des résultats ou des contenus proposés.
Le secteur automobile lui aussi investit ce terrain : la conduite autonome progresse rapidement sur voie rapide, moins sur route encombrée où la réalité se complique et rappelle parfois, tragiquement, les limites de la technologie.
Côté jeux, l’IA a déjà triomphé d’humains au Go, aux échecs, ou dans des univers vidéoludiques comme Starcraft. Même chose pour la traduction automatique, la détection d’émotions sur les réseaux, la reconnaissance vocale ou le diagnostic médical par lecture de radiographies, tous ces domaines s’appuient aujourd’hui sur le machine learning.
Dans le domaine médical, il arrive que les algorithmes repèrent des anomalies sur des radios avec une justesse inattendue. Mais ils restent à surveiller : dans des cas complexes, seule la nuance humaine fait la différence.
Prenons aussi l’exemple du recrutement. Des entreprises ont tenté de confier le tri des CV à l’apprentissage automatique. Rapidement, les biais présents dans les données d’origine se transmettent dans les résultats : discriminations répétées, exclusions de profils, suspicion généralisée. Depuis, certains acteurs majeurs du secteur ont interrompu ou revu ces outils, tandis que d’autres cherchent encore comment rendre ces algorithmes plus justes.
La reconnaissance faciale offre un autre terrain de débat : autrefois entraînés essentiellement sur des images d’hommes blancs, ces modèles commettaient bien plus d’erreurs avec d’autres types de visages. Trop souvent, la machine manque de recul sur sa propre pérennité.
Pourquoi utiliser l’apprentissage automatique avec le Big Data ?
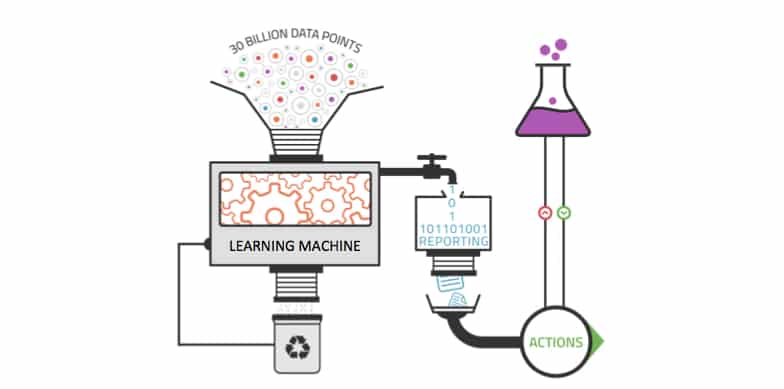
À l’heure où chaque seconde produit des torrents de données, les outils d’analyse traditionnels peinent à tenir la cadence. Le volume et la complexité du Big Data dépassent la capacité humaine à confronter toutes les hypothèses, à combiner toutes les variables ou à isoler chaque corrélation pertinente.
Les solutions historiques, comme la Business Intelligence ou les reportings automatisés, restent utiles pour générer des rapports et répondre à des requêtes ciblées. Mais leur champ d’action reste borné, dépendant d’une configuration manuelle, et s’essouffle dès que la diversité ou la quantité de données explose.
Comment cela fonctionne-t-il ?
L’apprentissage automatique lève ces obstacles. Il met à profit la richesse du Big Data pour débusquer des tendances invisibles, sans qu’une surveillance humaine soit nécessaire à chaque instant. Plus le flux de données s’accroît, plus le modèle fortifie ses prédictions et s’adapte à des configurations de plus en plus nuancées. Là où l’analyse humaine cale, la machine poursuit sans fatigue.
Cette aptitude à explorer de multiples origines de données, à traiter l’afflux ininterrompu d’informations, à s’auto-améliorer en continu, place le machine learning au centre de la valorisation des données massives.
Pourquoi l’apprentissage automatique n’est rien sans Big Data ?

S’il manque la matière brute des données, l’intelligence artificielle stagne. Ce sont bel et bien les informations récoltées qui donnent prise à l’apprentissage, la compréhension, la progression des systèmes. Avec l’accumulation rapide de volumes denses et variés, l’analyse devient plus fine, plus automatisée, plus rapide.
Il y a quelques années encore, la pénurie de données limitait sérieusement les ambitions de l’IA. Aujourd’hui, l’accès massif et continu à ces flux bouleverse la donne pour tous les acteurs, du géant mondial à la PME qui aspire à rivaliser par l’analyse de ses propres bases.
De nombreux exemples illustrent ce virage : les compagnies d’assurance, par exemple, optimisent désormais la gestion des sinistres grâce à des algorithmes qui scrutent aussi bien des bases structurées que des enregistrements vocaux. Le résultat est palpable : meilleure anticipation, prise en charge accélérée, gestion des risques plus précise.
Le Deep Learning, un sous-domaine de l’apprentissage automatique
L’apprentissage profond (Deep Learning) pousse encore plus loin la mécanique du machine learning. On le retrouve à l’œuvre partout où la reconnaissance d’images, de visages ou d’émotions est devenue monnaie courante. Reconnaître un individu sur une photo, capter un sourire à la sortie d’un magasin, décrypter la tonalité d’une voix : ces prouesses reposent sur ces architectures avancées.
Le deep learning s’inspire du cerveau, organisant ses modèles sous forme de couches reliées comme des neurones artificiels. Le type d’apprentissage varie selon le projet : parfois totalement supervisé, parfois non guidé, partiellement annoté, ou bien basé sur le transfert d’une solution d’un cas vers un autre.
Cette sophistication a un coût : il faut une montagne de données pour entraîner ces modèles, et des capacités de calcul considérables, très souvent accélérées par des infrastructures de type data lake. Impossible de bâtir des performances solides sans ce carburant massif.
Réseaux de neurones
Les réseaux de neurones artificiels empruntent leurs principes au cortex visuel humain. Ils fonctionnent en chaînes complexes, où chaque couche trie l’information et la transmet à la suivante pour affiner l’analyse.
Plus on multiplie les couches, plus les calculs deviennent exigeants. Pour soutenir ce rythme, on va au-delà des processeurs classiques et on mobilise des GPU, TPU ou FPGA, de quoi permettre à ces algorithmes complexes d’exprimer toutes leurs capacités.
L’analyse prédictive donne de l’importance au Big Data

L’analyse prédictive transforme l’histoire des données en boussole pour anticiper des tendances, affiner les stratégies économiques ou commerciales. Elle rassemble statistiques avancées, fouille de données, modèles prédictifs et apprentissage automatique pour offrir aux entreprises la possibilité d’estimer l’impact de décisions, de cerner les attentes des clients, ou de repérer des signaux ténus au bon moment.
Ce type d’analyse dégage de la valeur depuis des gisements longtemps inexploités. Il éclaire la stratégie, rend le parcours client plus fluide, donne aux décideurs une longueur d’avance. Les innovations récentes comme certains moteurs analytiques intégrés rendent ces outils abordables à un public bien plus large qu’autrefois.
Désormais, les systèmes dits cognitifs ne se contentent plus d’appliquer des recettes. Ils affinent leur apprentissage en continu, raisonnent sur des données non structurées, adaptent leur jugement à chaque interaction et s’efforcent de comprendre, de dialoguer ou même de ressentir. Mais tout cela exige des progrès constants dans l’analyse du langage et la modélisation de la complexité du réel.
L’apprentissage automatique au service de la gestion des données

L’accumulation incessante de données crée de nouveaux défis : explorer les informations dormantes, assurer une gestion cohérente de la conservation, fédérer les multiples sources pour fiabiliser l’analyse et simplifier le partage. Sur chacun de ces volets, l’apprentissage automatique fait la différence.
Année après année, les entreprises stockent d’immenses quantités de données, souvent inexploitées, surnommées données sombres. À l’appui d’algorithmes sur mesure, il devient possible de filtrer ces ressources, de pré-classer automatiquement les fichiers ou documents, puis de laisser la main à l’expert pour valider ou corriger le tri.
Les algorithmes interviennent aussi dans la gestion du stockage : ils détectent les fichiers inutiles ou anciens, suggèrent ceux à écarter et contribuent à un gain d’espace et de temps substantiel pour les équipes. Même si tri humain et tri algorithmique n’offrent pas la même finesse, la productivité y gagne clairement.
Pour coordonner l’import de données de sources très variées, les analystes développent des référentiels et de grandes zones d’analyse. L’intégration de ces données via le machine learning permet de créer des correspondances rapidement entre l’origine et la destination des flux. Au final : une agrégation plus rapide, une intégration bien plus souple.
Les fournisseurs de solutions de stockage ne sont pas en reste. Leurs moteurs automatiques repèrent les fichiers les plus sollicités, optimisent leur emplacement et limitent la pression sur les ressources. Grâce au recul des prix du SSD, ce type de technologie n’est plus réservé à une poignée de grandes structures.
Une mauvaise forme d’IA
Dans les entreprises, beaucoup rappellent que l’intelligence artificielle n’en est qu’à ses prémices. L’apprentissage automatique demeure, aujourd’hui, une forme de machine learning qui reste relativement simple, même si elle a déjà fait tomber bien des barrières. Cette technologie sait traiter des images, des sons, du texte, ou exécuter efficacement des tâches très répétitives. Pour construire des systèmes vraiment intelligents, il faut associer et faire dialoguer plusieurs algorithmes, comme on le voit sur les chantiers de la voiture autonome. Pourtant, le secteur avance trop souvent en silos : chacun développe dans son coin. L’intelligence collective, elle, n’a pas encore trouvé son moteur.
Le Big Data était annoncé comme une vague, puis un ouragan. L’apprentissage automatique, lui, façonne cette matière première. Entre données massives et algorithmes affamés, le jeu se joue désormais sur notre capacité à relier, trier, faire parler tout ce qui, hier encore, dormait dans les serveurs.